

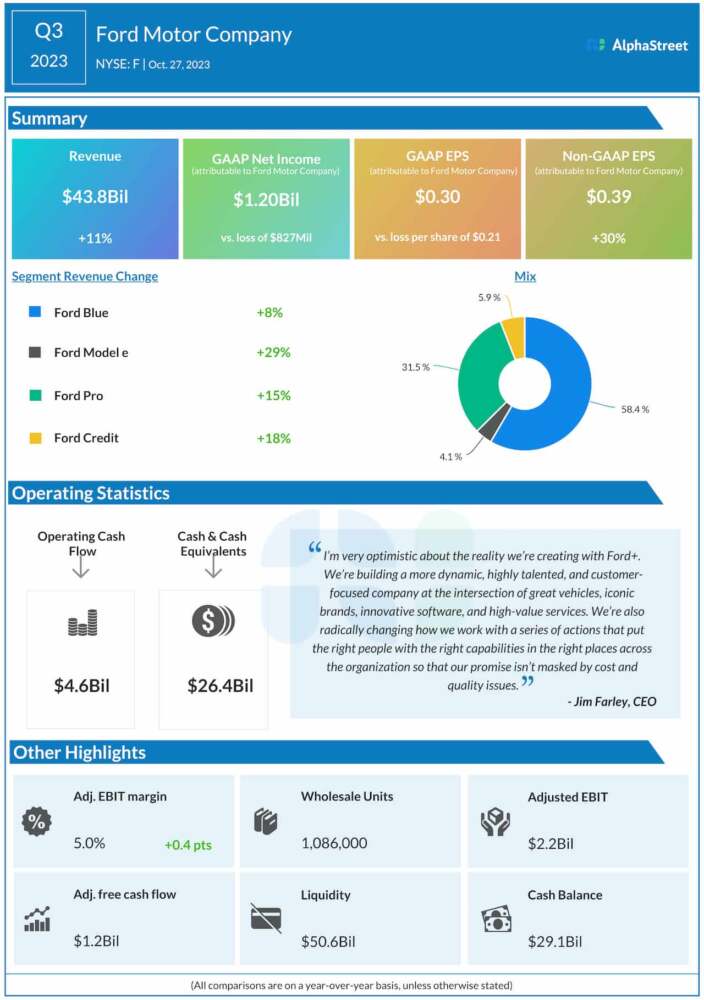
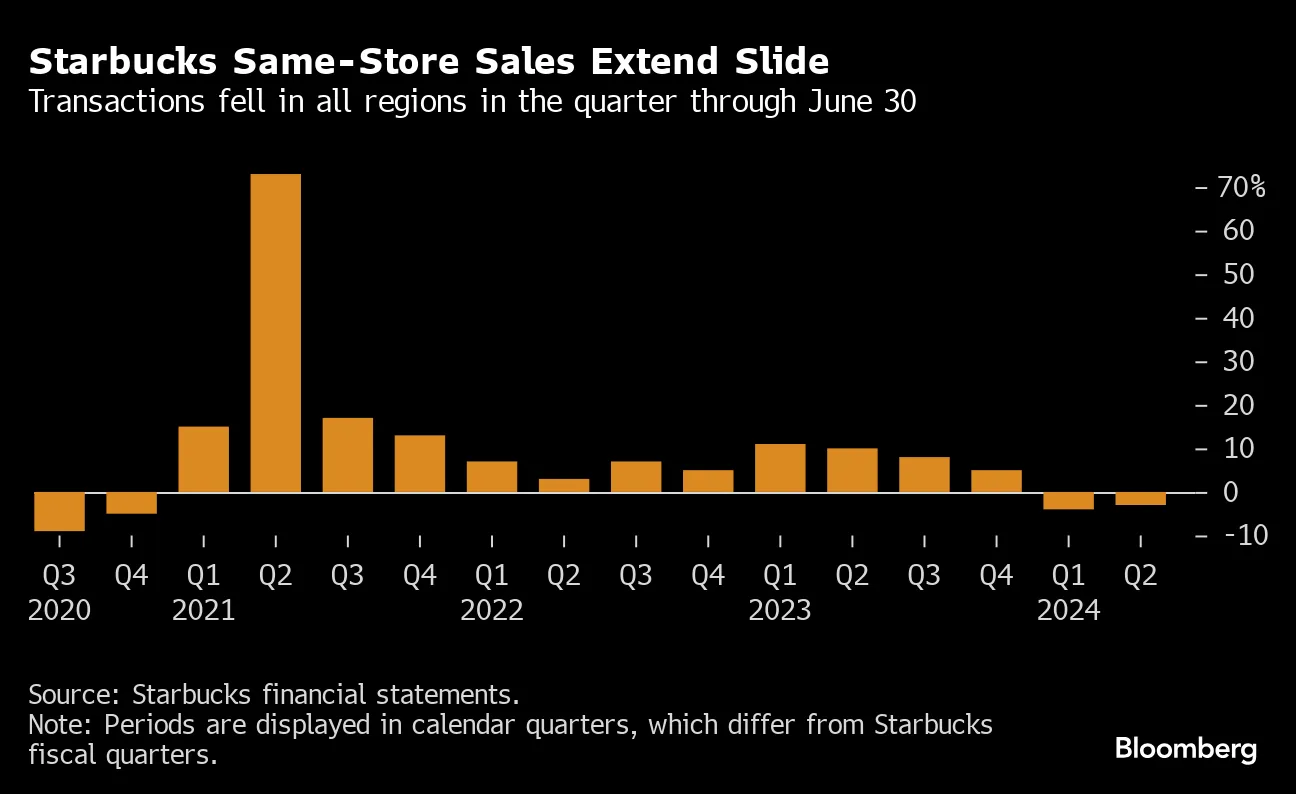
Millions of users around the world faced widespread disruption when key Microsoft services—including Outlook email and the Teams collaboration platform—experienced a significant outage that lasted for several hours. The interruption affected individuals, businesses, schools, and organizations that rely on Microsoft’s cloud‑based productivity tools for daily communication and work coordination.
The incident began late in the morning, with users reporting issues accessing their Outlook mailboxes, joining Teams meetings, and using other Microsoft 365 applications. Within minutes, reports of service failures spiked dramatically as frustrated users discovered they could not send or receive emails, start video calls, or even access shared calendars. Many businesses found their internal workflows severely disrupted as both communication and scheduling ground to a halt.
How Services Were Affected
The outage was not limited to a single application; it spanned multiple core services:
- Outlook Mail: Users encountered login errors, delayed delivery, and failure to sync messages across devices. Many reported that important business emails could not be sent or received at critical moments.
- Microsoft Teams: The collaboration platform, which many organizations use for video conferencing, instant messaging, and file sharing, also went dark for many users. Meetings were dropped or could not be joined, and chat functions became unavailable.
- Microsoft 365 Apps: Broader parts of Microsoft’s cloud ecosystem—including online versions of Word, Excel, and OneDrive—also experienced connectivity issues due to their reliance on shared infrastructure.
The simultaneous disruption across multiple services highlighted how deeply integrated Microsoft’s technologies are in modern work environments. For many remote teams and hybrid workplaces, the outage effectively eliminated key avenues for communication and productivity.
Microsoft’s Response and Restoration Efforts
Microsoft quickly acknowledged the situation, stating that engineers were investigating the source of the problem and working to restore services as swiftly as possible. The company indicated that the outage stemmed from failures in core infrastructure systems that route traffic and authentication requests for user accounts.
Engineers undertook extensive traffic rerouting and load‑balancing measures designed to divert workloads to unaffected systems while repairs were underway. Microsoft’s service monitoring teams worked through much of the afternoon to bring services back online.
Gradually, Outlook and Teams functions began returning to normal, although some users continued to experience intermittent issues as stability improved. By late afternoon and early evening, most productivity tools had resumed typical operation, though some residual delays in message delivery and meeting connections were still being reported.
Impact Across Work and Daily Life
The outage struck at a time when many businesses were coordinating key projects, scheduling meetings, and managing deadlines—relying heavily on Microsoft’s ecosystem. Schools using Teams for virtual classrooms, corporate teams conducting remote work, and individuals managing email communication all felt the impact. Organizations scrambled to switch to alternative platforms like third‑party email accounts and video‑conference services to maintain communication flow.
For many IT departments, the disruption also underscored the risks of dependence on a single provider for multiple mission‑critical services. The outage sparked discussions about the need for robust contingency plans and diversified technology strategies to mitigate similar events in the future.
Looking Ahead: Strengthening Cloud Resilience
Microsoft reassured customers that it is reviewing the root causes of the outage and will invest in infrastructure improvements to prevent future widespread disruptions. While outages are not uncommon in large cloud environments, the scale of this incident highlighted just how critical such platforms have become to global business operations.
In the wake of the outage, organizations and users alike are expected to revisit disaster recovery plans and consider backup solutions that ensure continuity when primary services fail. The lessons learned from this event could well shape how companies approach cloud dependency in the years ahead.











Leave a Reply